


A major drawback to the DP methods that we have discussed so far is that
they involve operations over the entire state set of the MDP, that is, they
require sweeps of the state set. If the state set is very large, then even a
single sweep can be prohibitively expensive. For example, the game of
backgammon has over 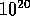 states. Even if we could perform the value
iteration backup on a million states per second, it would take over a thousand
years to complete a single sweep.
states. Even if we could perform the value
iteration backup on a million states per second, it would take over a thousand
years to complete a single sweep.
Asynchronous DP algorithms are in-place iterative DP algorithms that are not organized in terms of systematic sweeps of the state set. These algorithms back up the values of states in any order whatsoever, using whatever values of other states happen to be available. The values of some states may be backed up several times before the values of others are backed up once. To converge correctly, however, an asynchronous algorithm must continue to backup the values of all the states: it can't ignore any state after some point in the computation. Asynchronous DP algorithms allow great flexibility in selecting states to which backup operations are applied.
For example, one version of asynchronous value iteration backs up the value, in
place, of only one state, 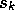 , on each step, k, using the value
iteration backup (4.10). If
, on each step, k, using the value
iteration backup (4.10). If 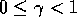 , asymptotic
convergence to
, asymptotic
convergence to
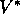 is guaranteed given only that all states occur in the sequence
is guaranteed given only that all states occur in the sequence 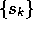 an
infinite number of times. (In the undiscounted episodic case, it
is possible that there are some orderings of backups that do not result in
convergence, but it is relatively easy to avoid these).
Similarly, it is possible to intermix policy evaluation
and value iteration backups to produce a kind of asynchronous truncated
policy iteration. Although the details of this and other more unusual DP algorithms
are beyond the scope of this book, it is clear that a few different backups
form building blocks that can be used flexibly in a wide variety of
sweep-less DP algorithms.
an
infinite number of times. (In the undiscounted episodic case, it
is possible that there are some orderings of backups that do not result in
convergence, but it is relatively easy to avoid these).
Similarly, it is possible to intermix policy evaluation
and value iteration backups to produce a kind of asynchronous truncated
policy iteration. Although the details of this and other more unusual DP algorithms
are beyond the scope of this book, it is clear that a few different backups
form building blocks that can be used flexibly in a wide variety of
sweep-less DP algorithms.
Of course, avoiding sweeps does not necessarily mean that we can get away with less computation. It just means that an algorithm does not need to get locked into any hopelessly long sweep before it can make progress improving a policy. We can try to take advantage of this flexibility by selecting the states to which we apply backups so as to improve the algorithm's rate of progress. We can try to order the backups to let value information propagate from state to state in an efficient way. Some states may not need their values backed up as often as others. We might even try to skip backing up some states entirely if they are not relevant to optimal behavior. Some ideas for doing this are discussed in Chapter 9.
Asynchronous algorithms also make it easier to intermix computation with real-time interaction. To solve a given MDP, we can run an iterative DP algorithm at the same time that an agent is actually experiencing the MDP. The agent's experience can be used to determine the states to which the DP algorithm applies its backups. At the same time, the latest value and policy information from the DP algorithm can guide the agent's decision making. For example, we can apply backups to states as the agent visits them. This makes it possible to focus the DP algorithm's backups onto parts of the state set that are most relevant to the agent. This kind of focusing is a repeated theme in reinforcement learning.