Reinforcement Learning and Information Access
or
What is the Real Learning Problem
in Information Access?
Introductory Patter
In this talk we will try to take a new look at the
learning problem in information access. How is it structured? What
training information is really available, or likely to be available?
Will there be delays between decision making and the receipt of relevant
feedback? I am a newcomer to information access, but I have experience in reinforcement learning, and one of the main lessons of
reinforcement learning is that it is really important to understand the
true nature of the learning problem you want to solve.
Here is an example that illustrates the whole idea. In 1989 Gerry
Tesauro at IBM built the world's best computer player of backgammon. It
was a neural network trained from 15,000 examples of human-expert
moves. Then he tried a reinforcement learning approach. He trained the
same network not from expert examples, but simply by playing it against
itself and observing the outcomes. After a month of self-play, the program
became the new world champ of computers. Now it is an extremely strong
player, on a par with the world's best grandmasters, who are now
learning from it! The self-play approach worked so well
primarily because it could generate new training data itself. The
expert-trained network was always limited by its 15,000 examples,
laboriously constructed by human experts. Self-play training data may
be individually less informative, but so much more of it can be
generated so cheaply that it is a big win in the long run.
The same may be true for information access. Right now we use training
sets of documents labeled by experts as relevant or not relevant. Such
training data will always be expensive, scarce, and small. How much
better it would be if we could generate some kind of training data
online, from the normal use of the system. The data may be imperfect
and unclear, but certainly it will be plentiful! It may also be truer in
an important sense. Expert-labeled training sets are artificial, and do not
accurately mirror real usage. In backgammon, the expert-trained system
could only learn to mimic the experts, not to win the game. Only
the online-trained system was able to learn to play better than the
experts. Its training data was more real.
This then is the challenge: to think about information access and
uncover the real structure of the learning problem. How can learning be
done online? Learning thrives on data, data, data! How can we get the
data we need online, from the normal operation of the system, without
relying on expensive, expert-labeled training sets?
This talk proceeds in three parts. The first is an introduction to
reinforcement learning. The second examines how parts of the
learning problem in information access are like those solved by
reinforcement learning methods. But the information access problem doesn't map exactly onto
the reinforcement learning problem. It has a special structure all it own. In the third
part of the talk we examine some of this special structure and what kind
of new learning methods might be applied to it.
The rest below are approximations to the slides presented in
the talk.
Conclusions (in advance)
- Learning in IA (Information Access) is like learning everywhere
- you are never told the right answers
- its a sequential problem - actions affect opportunities
- Reinforcement Learning addresses these issues
- Learning can be powerful when done online (from normal operation)
- What is online data/feedback like in IA?
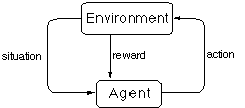
Reinforcement Learning
- Learning by trial and error, rewards and punishments,
- Active, multidisciplinary research area
- An overall approach to AI
- based on learning from interaction with the environment
- integrates learning, planning, reacting...
- handles stochastic, uncertain environments
- Recent large-scale, world-class applications
- Not about particular learning mechanisms
- Is about learning with less helpful feedback
Classical Machine Learning - Supervised Learning
situation1 ---> action1 then correct-action1
situation2 ---> action2 then correct-action2
.
.
.

- correct action supplied
- objective is % correct
- actual actions have no effect
- each interaction is independent, self contained
Reinforcement Learning
situation1 ---> action1
reward2 situation2 ---> action2
reward3 situation3 ---> action3
.
.
.
- agent never told which action is correct
- agent told nothing about actions not selected
- actions may affect next situation
- object is to maximize all future rewards
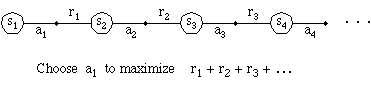
It's not just a harder problem, it's a real problem
- Problems with relevance feedback:
- what about all the documents not shown?
- the exploration-exploitation dilemma
- degrees of relevance
- We don't want to make user happy only in the short term
- Many solutions require sequences of steps
how do you support the early steps?
- SL can't be used reliably on-line (except for immed. prediction)
can't learn from normal operation
Applications of RL
- TD-Gammon and Jellyfish -- Tesauro, Dahl
- Elevator control -- Crites
- Job-shop scheduling -- Zhang & Dietterich
- Mobile robot controllers -- Lin, Miller, Thrun, ...
- Computer Vision -- Peng et al.
- Natural language / dialog tuning -- Gorin, Henis
- Characters for interactive games -- Handelman & Lane
- Airline seat allocation -- Hutchinson
- Manufacturing of Composite materials -- Sofge & White
Key Ideas of RL Algorithms
Value Functions
- Like a heuristic state evaluation function -- but learned
- Approximates the expected future reward after a state or action
- The idea: learn "how good" an action is,
rather than whether or not it is the best,
taking into account long-term affects
- Value functions vastly simplify everything
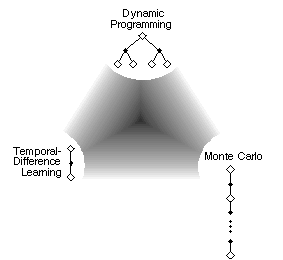
TD Methods
- An efficient way of learning to predict (e.g., value functions)
from experience and search
- Learning a guess from a guess
A Large Space of RL Algorithms
Major Components of an RL Agent
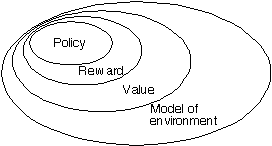
Policy - what to do
Reward - what is good
Value - what is good because it predicts reward
Model - what follows what
Info-Access Applications of RL
Anytime you have decisions to be made
and desired choice is not immediately clear
Anytime you want to make long-term predictions
Classical IR Querying/Routing/Filtering as RL
Situation = Query or user model + Documents
Actions = Present document? Rankings
Reward = User feedback on presented docs
Pro RL:
Feedback is selective
and does not exactly fit SL framework
Con RL:
Feedback does not exactly fit RL framework
Problem is not sequential
e.g.,
Bartell, Cottrell & Belew, 1995
Boyan, Freitag & Joachim 1996
Schźtze, Hull & Pederson, 1995
MultiStep Info-Access Problems
- Query/Search Optimization
- Entertainment
- Software IR Agents
- Information Assistant
- Routing/Filtering
- Interface Manager
- Web Browsing
- Anticipating User
But in a sense all these are the same
Learning a complex, interactive, goal-directed, input-sensitive, sequence of steps
That's exactly what RL is good for.
The Multi-Step, Sequential Nature of IA
- the web page that led to the web page
- the request of user that enabled a much better query
- the query whose results enabled user to refine his next query
- the ordering of search steps
- the document that turned out NOT to be useful
- the series of searches, each building on the prior's results
Imagine an Ideal Info-Access System
- Continuous oportunity to provide query info:
- keywords, type specs, feedback
- Continuously updated list of proposed documents
- find the good ones as soon as possible!
- Actions: all the things that could be done to pursue the search
- when, where to send queries (Alta Vista? Yahoo? ...)
- when, what to ask user (synonyms, types, utilities...)
- what documents to propose
- which links to follow
- who else to consult
- Situations: the whole current status of the search
- Reward: good and bad buttons, maintaining interest, etc
- Value: how good is this action? what rewards will it lead to?
Shortcutting
- Feedback is often more than good/bad
- Often it does indicate the desired response
- not for the one situation,
- but for the whole sequence of prior situations
- Each good document is
- a positive example - this is what I was looking for
- a negative example - why wasn't this found earlier?
- The result of each search can be generalized, learned, anticipated, shortcutted
- This "anticipation" process is similar to certain RL processes...
Compare...
The classical context
- Large numbers of documents (e.g., 2 million)
- a few queries (e.g., 200)
No way the queries can be used to learn about the docs
The Web
- Large numbers of documents
- Even more queries
There will always be more readings than writings
Thus, we can learn about the docs
- How good are they?
- Who are they good for?
- What keywords are appropriate for them?
Popularity Ratings, Priors on Documents
Q. How do you decide what to access today?
- scientific papers, books, movies, web pages...
A. Recommendations:
- reviewed journals
- movie critics
- cool site of the day
- # visitors to site
- what your colleagues are talking about
"Its hard to find the good stuff on the web"
But in classical IR there is no concept of good stuff
docs are relevant or not, but not good or bad
Differences and Similarities between Users
- Now users provide feedback as a favor, to help others,
or because they are paid or the program forces them to
- They ought to be providing feedback for selfish reasons
- Suppose you had a personal research assistant...
wouldn't you tell him what you liked and didn't like?
- user differences ==> selfish feedback ==> known user similarities
Summary
- Data is power! What relevant data is/will be available?
- Relevance vs Utility
- Independent vs Multi-Step Queries
- Shortcutting
- Collaborative Filtering
- Selfish Feedback
- Learning classifications that help